K-Means Algorithm Python Example
In this post, we will provide an example of the implementation of the K-Means algorithm in python. This K-Means algorithm python example consists of clustering a dataset that contains information of all the stocks that compose the Standard & Poor Index.
This example contains the following five steps:
- Obtain the 500 tickers for the SPY & 500 by scrapping the tickers symbols from Wikipedia. The function obtain_parse_wike_snp500() conduct this task.
- Obtain closes prices from last year for each of the symbols using the Quandl API
- Calculate mean and variance of the returns for each stock
- Choose the best k value for the cluster the dataset
- Fit the model with the k number of cluster
1import pandas as pd
2import numpy as np
3from math import ceil
4import bs4
5import requests
6import quandl # need to do pip install quandl
7from sklearn.cluster import KMeans
8import matplotlib.pyplot as plt
9
10
11def obtain_parse_wiki_snp500():
12 """ Download and parse the Wikipedia list of S&P500 constituents using requests and Beautiful Soup.
13 """
14
15 response = requests.get( "http://en.wikipedia.org/wiki/List_of_S%26P_500_companies" )
16
17soup = bs4.BeautifulSoup(response.text)
18
19 # This selects the first table, using CSS Selector syntax and then ignores the header row ([1:])
20 symbolslist = soup.select('table')[0].select('tr')[1:]
21
22 # Obtain the symbol information for each row in the S&P500 constituent table
23 symbols = []
24 for i, symbol in enumerate(symbolslist):
25 tds = symbol.select('td')
26 symbols.append( (tds[0].select('a')[0].text, # Ticker
27 tds[1].select('a')[0].text, # Name
28 tds[3].text # Sector
29 )
30 )
31
32 return symbols
33
34tickers = obtain_parse_wiki_snp500()
35The tickers object is a list of tuples with the ticker, company name and sector of each company. To observe the structure of the tickers object we show the first 10 elements.
1tickers[:10]
2
3[('MMM', '3M Company', 'Industrials'),
4 ('ABT', 'Abbott Laboratories', 'Health Care'),
5 ('ABBV', 'AbbVie Inc.', 'Health Care'),
6 ('ABMD', 'ABIOMED Inc', 'Health Care'),
7 ('ACN', 'Accenture plc', 'Information Technology'),
8 ('ATVI', 'Activision Blizzard', 'Communication Services'),
9 ('ADBE', 'Adobe Systems Inc', 'Information Technology'),
10 ('AMD', 'Advanced Micro Devices Inc', 'Information Technology'),
11 ('AAP', 'Advance Auto Parts', 'Consumer Discretionary'),
12 ('AES', 'AES Corp', 'Utilities')]
13We will use this list in the following function to loop over each symbol of tickers and get the close price from the Quandl API. We perform the loop using a try-except block to handle errors regarding symbols that were changed or are different in the Quandl database.
1def get_quandl_data(symbols):
2 """
3 This function would loop over all the symbols from the SPY & 500 and retrieve the Close price column from the WIKI database from Quandl between the dates given by the start_date and end_date parameters
4 """
5
6 symbols = [symbol[0] for symbol in symbols]
7 stocks_info = []
8
9 for symbol in symbols:
10 try:
11 stockdata = quandl.get("WIKI/{}".format(symbol), start_date='2018-09-20', end_date='2019-09-20',column_index=4)
12 print('Downloading data from symbol {}'.format(symbol))
13 stocks_info.append((symbol,stockdata.iloc[:,0]))
14 except:
15 print('The stock symbol {} is not on quandl database'.format(symbol))
16
17 return stocks_info
18
19data = get_quandl_data(tickers)
20The data object is a list of tuples where each tuple has 2 elements. The first element is the ticker and the second element is the Date and Close Price for each of the stocks. We need to parse this information in order to make a dataframe that has the date as index and the close prices for each stock as columns. The following lines will do this job:
1# Get only the symbols from the data object
2symbols = [data[i] for i in range(0,len(data))]
3# Get the date and prices from the data object (second element of the tuple)
4closes = [data[i][1] for i in range(0,len(data))]
5
6# Store closes object in a dataframe and obtain the transpose of the dataframe. #With this we will have the Date as index and the Prices of each stock as columns.
7closes = pd.DataFrame(closes).T
8# Rename column names with the symbols list
9closes.columns = symbols
10#Calculating annual mean returns and standard deviation of the returns
11returns = closes.pct_change().mean() * 252
12std = closes.pct_change().std() * np.sqrt(252)
13
14#Concatenating the returns and variances into a single data-frame
15ret_var = pd.concat([returns, std], axis = 1).dropna()
16ret_var.columns = ["Returns","Standard Deviation"]
17The ret_var dataframe has the following structure:
1ret_var.head(10)
2
3 Returns Standard Deviation
4MMM 0.301229 0.122294
5ABT 0.392332 0.138839
6ABBV 0.457778 0.179314
7ABMD 0.545361 0.242094
8ACN 0.284499 0.131696
9ATVI 0.596721 0.305587
10ADBE 0.554549 0.216873
11AMD 0.069001 0.585976
12AAP -0.460970 0.394637
13AES -0.052332 0.210608
14In order to determine the optimal number of clusters k for the ret_var dataset, we will fit different models of the K-means algorithm while varying the k parameter in the range 2 to 14. For each model we calculate the Sum Squared Error (SSE) by using the inertia_ method of the model fitted. In each iteration we append the inertia to the sse list. Then we take the model with the less value of SSE. (Inertia tells how far away the points within a cluster are. The small the inertia value is better.)
1#Converting ret_var into numpy array
2X = ret_var.values
3sse = []
4for k in range(2,15):
5 kmeans = KMeans(n_clusters = k)
6 kmeans.fit(X)
7
8 #SSE for each n_clusters
9 sse.append(kmeans.inertia_)
10
11plt.plot(range(2,15), sse)
12plt.title("Elbow Curve")
13plt.show()
14The graph is names as Elbow Curve, and shows that the optimal value of k is 5.
Elbow Curve: Determine the optimal value of k. K-means Cluster
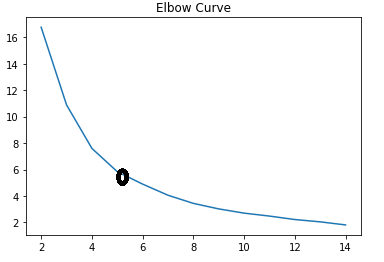
We chose k=5 and fit the model with this parameter-value.
1kmeans = KMeans(n_clusters = 5).fit(X)
2centroids = kmeans.cluster_centers_
3plt.scatter(X[:,0],X[:,1], c = kmeans.labels_, cmap ="rainbow")
4plt.show()
5The different groups or cluster of the dataset are reflected in the following graph:
Clusters of the ret_var dataset. k=5
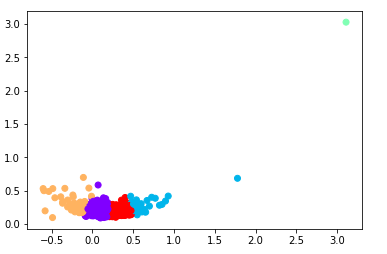
We can view the presence of outliers as only one point is on the upper right side of the graph. This outlier form its own cluster. In order to have a better categorization of the stocks within the SPY index, we would remove those stocks and fit the model another time.
1# Find the stock with the highest value in the Standard Deviation variable
2stdOrder = ret_var.sort_values('Standard Deviation',ascending=False)
3first_symbol = stdOrder.index[0]
4
5# Drop the columns with the outliers values
6ret_var.drop(first_symbol,inplace=True)
7# Fit the model without the outliers
8X = ret_var.values
9kmeans =KMeans(n_clusters = 5).fit(X)
10centroids = kmeans.cluster_centers_
11plt.scatter(X[:,0],X[:,1], c = kmeans.labels_, cmap ="rainbow")
12plt.show()
13Clusters of ret_var dataset without Outliers. k=5
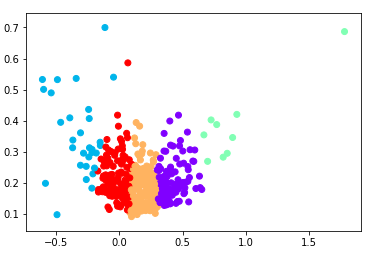
The x axis of the Figure 17, refers to the returns of the stocks and the y axis is the standard deviation of each stock. So the stocks that are in the upper-right cluster are the stocks with the higher value of returns and standard deviation.
Finally we will assign to each stock it correspondent number of cluster(1,2,3,4,and 5) and make a dataframe with this information. Having the information of cluster number for each stock, we can create a diversified portfolio in the long term, between stocks from different clusters.
1stocks = pd.DataFrame(ret_var.index) # the dataframe structure allow concatenation
2cluster_labels = pd.DataFrame(kmeans.labels_)
3stockClusters = pd.concat([stocks, cluster_labels],axis = 1)
4stockClusters.columns = ['Symbol','Cluster']
5The structure of the stockClusters dataframe is the following:
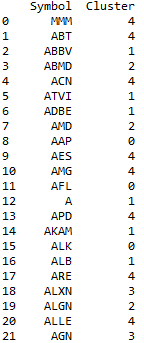
These are the first rows of the stockClusters dataframe. We conclude this section with a categorization of each stock from the SPY & 500 in terms of returns and risk. This could be an important tool for portfolio diversification. This concludes our K-Means algorithm python example.
