Feature Selection in Machine Learning
Feature Selection is one of the core concepts in machine learning and has a high impact on the performance of the model. Irrelevant or partially irrelevant features can negatively impact the model performance.
In this process, those features which contribute most to the prediction variable are selected. In order to get an idea about which features could have more predictive power in a machine learning model, we will load Open, High, Low, Close, Volume (OHLCV) data for AMZ stock, and create some new features using Python.
Afterwards, we will use data visualizations and other common approaches for a smart selection of the features.
We will be performing this process using Python. The example below has 4 main steps:
- Import the Python libraries that will be used.
- Calculate Technical Indicators with the
get_technical_indicators()function. - Plot scatterplots among features and target variable
_AdjClose._ - Make a Heat Map to show the correlation between each of the features and the target variable.
- Fit a Random Forest Model to extract feature importance of the independent variables (we will explain this algorithm in future sections but now will use some of the tools that Random Forest provides).
1import pandas as pd
2import matplotlib.pyplot as plt
3import numpy as np
4import seaborn as sns
5from sklearn.ensemble import RandomForestRegressor
6The data for AMZ stock is loaded into the environment using the read_csv() method.
1# To read the file, make sure to provide path to the correct directory in your computer.
2
3amz = pd.read_csv("C:/Users/Nicolas/Documents/Machine_Learning_Course/AMZ.csv")
4We use the amz object dataframe which has OHLCV data from AMZ ticker and pass into the get_technical_indicators() function. This function generates technical indicators to be used as features for a machine learning model.
1def get_technical_indicators(dataset):
2 '''
3 params:
4 dataset: OHLCV data for AMZ ticker from 1999-09-01 to 2019-09-20
5 returns
6 features dataframe with the calculations of all technical Indicators such as
7 MACD, 20 period’s standard deviation, ROC, CCI, EMA
8 '''
9 # Sort values by dates. Old dates at top
10 dataset.sort_index(inplace=True)
11 # Create the features dataframe to store only the features
12 features = pd.DataFrame(index=dataset.index)
13
14 # Create 7 and 21 days Moving Average
15 features['ma7'] = dataset['AdjClose'].rolling(window=7).mean()
16 features['ma21'] = dataset['AdjClose'].rolling(window=21).mean()
17
18 # Create MACD
19 features['26ema'] = dataset['AdjClose'].ewm(span=26).mean()
20 features['12ema'] = dataset['AdjClose'].ewm(span=12).mean()
21 features['MACD'] = (features['12ema']-features['26ema'])
22
23 # Create Bollinger Bands
24 features['20sd'] = dataset['AdjClose'].rolling(20).std()
25 features['upper_band'] = features['ma21'] + (features['20sd']*2)
26 features['lower_band'] = features['ma21'] - (features['20sd']*2)
27
28 # Create Exponential moving average
29 features['ema'] = dataset['AdjClose'].ewm(span=20).mean()
30
31 # ROC Rate of Change
32 N = dataset['AdjClose'].diff(10)
33 D = dataset['AdjClose'].shift(10)
34 features['ROC'] = N/D
35
36 # CCI Commodity Channel Index
37 TP = (dataset['High'] + dataset['Low'] + dataset['AdjClose']) / 3
38 features['CCI'] = (TP - TP.rolling(20).mean()) / (0.015 * TP.rolling(20).std() )
39 # Create Average True Range
40 features['TR'] = dataset['High'] - dataset['Low']
41 features['ATR'] = features['TR'].ewm(span = 10).mean()
42
43 return features
44
45
46# Store the output of get_technical_indicators() function in the features object
47
48features = get_technical_indicators(amz)
49The features object stores all the calculations of the get_technical_indicators() function.
1# Retrieve the features that will be used in the vars_ dataframe
2vars_ = features[['MACD','20sd','TR','ma21','ROC','CCI']]
3
4# The correlation() function would make scatterplots between each of the features and the target variable AdjClose
5
6jet= plt.get_cmap('jet')
7colors = iter(jet(np.linspace(0,1,10)))
8
9def correlation(df,features,variables, n_rows, n_cols):
10 fig = plt.figure(figsize=(8,6))
11 #fig = plt.figure(figsize=(14,9))
12 for i, var in enumerate(variables):
13 ax = fig.add_subplot(n_rows,n_cols,i+1)
14 asset = features.loc[:,var]
15 ax.scatter(df["AdjClose"], asset, c = next(colors))
16 ax.set_xlabel("AdjClose")
17 ax.set_ylabel(" {}".format(var))
18 ax.set_title(var +" vs AdjClose")
19 fig.tight_layout()
20 plt.show()
21
22columns = vars_.columns
23correlation(amz,vars_,columns,2,3)
24Figure 1: Feature Selection Scatterplots
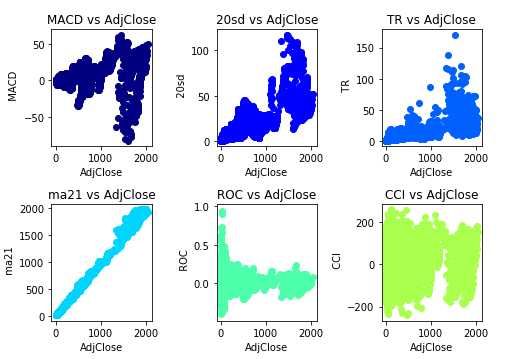
The scatterplot shows that there is an extremely positive correlation between the ma21 variable and the AdjClose. We can also visualize that there is a positive correlation between the 20sd and the TR variables with the target variable AdjClose.
On the other hand, there is a weak correlation of the features CCI and MACD with the target variable AdjClose.
Heat Maps are another tool that we can use to explore the relevance of each feature with respect to the target variable. The following lines make a Heat Map between the features and the target variable:
1# Copy the vars_ dataframe into a new dataframe called df.
2# Add the target variable to the vars_ dataframe to make a correlation matrix among features and target variable. Finally show a Heat Map with the values of the correlation matrix.
3
4df = vars_.copy()
5df['AdjClose'] = amz['AdjClose']
6
7colormap = plt.cm.inferno
8plt.figure(figsize=(10,5))
9corr = df.corr()
10sns.heatmap(corr[corr.index == 'AdjClose'], linewidths=0.1, vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True);
11plt.show()
12Figure 2: Heat Map between AdjClose variable and features
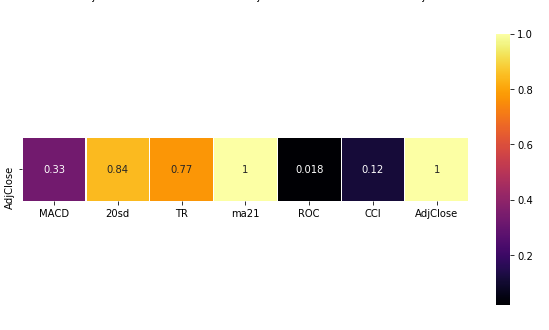
From the Heat Map we observe that the ma21 has perfect correlation with the AdjClose variable. Also 20sd and TR have positive correlation with the AdjClose, while the MACD and CCI don’t show significant correlation with AdjClose.
Lastly, we will use a method that is provided on the Random Forest algorithm that gives information about the feature importance. Firstly, we need to fit the model and then utilize the method called feature_importance_ (these steps are explained in next sections, but here we want to inspect feature_importance_ method ) on the model object.In the next line, we will fit a Random Forest Regressor model between the features and the target variable of the model, and extract the features_importance_ method. Finally we make a bar plot of the features importance measure.
1# Fit Random Forest Regressor and extract feature importance
2prices = pd.DataFrame(amz['AdjClose'])
3vars_model = prices.join(vars_)
4vars_model= vars_model.dropna()
5
6X = vars_model[['MACD','20sd','TR','ROC','CCI']].values
7y = vars_model['AdjClose'].values
8
9forest = RandomForestRegressor(n_estimators=1000)
10forest = forest.fit(X, y)
11importances = forest.feature_importances_
12
13values = list(zip(vars_model.columns[1:],importances))
14headers = ['feature','score']
15values_df = pd.DataFrame(values,columns = headers)
16
17# Plot the feature importance
18columns = ['MACD','20sd','TR','ROC','CCI']
19nd = np.arange(len(columns))
20width=0.5
21fig = plt.bar(nd, values_df['score'].values, color=sns.color_palette("deep", 5))
22plt.legend(fig, columns, loc = 'upper right',bbox_to_anchor=(1.1, 1), title = "Feature Importance")
23plt.show()
24Figure 3: Feature Importance
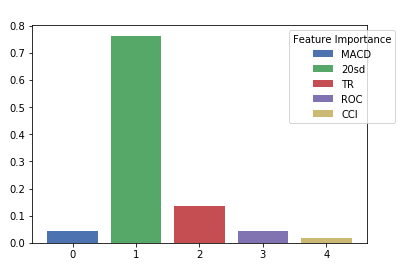
The bar plot of the feature importance show that 20sd has the greater importance in the prediction of the target variable AdjClose. On the second place comes the TR feature with significantly lower importance.
In this section we provided some tools to analyze the power prediction of the features before start to training a Machine Learning model. Is important to inspect the independent variables first for selecting the best features.
After the inspection of the features, the next step consists in the training and testing steps where is necessary to split the data among the train and test data. This is explained in the following section.
