Support Vector Machine (SVM) Model in R
A support vector machine (SVM) is a supervised learning technique that analyzes data and isolates patterns applicable to both classification and regression. The classifier is useful for choosing between two or more possible outcomes that depend on continuous or categorical predictor variables. Based on training and sample classification data, the SVM algorithm assigns the target data into any one of the given categories. The data is represented as points in space and categories are mapped in both linear and non-linear ways.
For SVM, we use Radial Basis as a kernel function. Due to limited computation reason, we use 5% of downsampling data for tuning parameter and 10% of downsampling data for training.
1set.seed(200)
2samp = downSample(data_train[-getIndexsOfColumns(data_train, c( "loan_status") )],data_train$loan_status,yname="loan_status")
3> table(samp$loan_status)
4
5 Default Fully.Paid
6 12678 12678
7>
81#choose small data for tuning
2train_index_tuning = createDataPartition(samp$loan_status,p = 0.05,list=FALSE,times=1)
3#choose small data for re-train
4train_index_training = createDataPartition(samp$loan_status,p = 0.1,list=FALSE,times=1)
51library(“kernlab”)
2svmGrid = expand.grid(
3 .sigma = as.numeric(sigest(loan_status ~.,data = samp[train_index_tuning,],scaled=FALSE)),
4 .C = c(0.1,1,10)
5 )
6
7svmTuned = train(
8 samp[train_index_tuning,-getIndexsOfColumns(samp,"loan_status")],
9 y = samp[train_index_tuning,"loan_status"],
10 method = "svmRadial",
11 tuneGrid = svmGrid,
12 metric = "ROC",
13 trControl = ctrl,
14 preProcess = NULL,
15 scaled = FALSE,
16 fit = FALSE)
17plot(svmTuned)
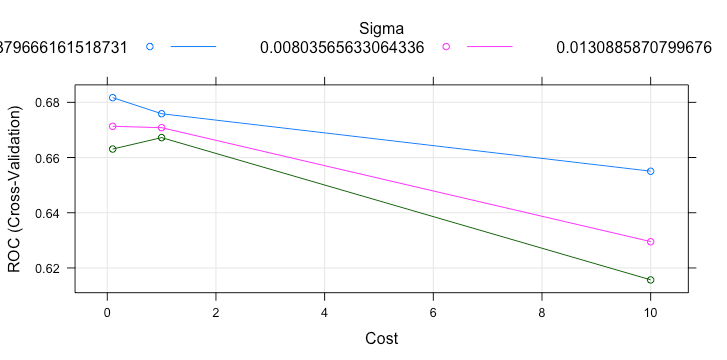
1> svmTuned
2Support Vector Machines with Radial Basis Function Kernel
31268 samples
4 70 predictor
5 2 classes: 'Default', 'Fully.Paid'
6No pre-processing
7Resampling: Cross-Validated (3 fold)
8Summary of sample sizes: 845, 845, 846
9Resampling results across tuning parameters:
10 sigma C ROC Sens Spec
11 0.003796662 0.1 0.6817007 0.5912024 0.6639021
12 0.003796662 1.0 0.6758736 0.6261886 0.6388193
13 0.003796662 10.0 0.6550318 0.6151599 0.5899431
14 0.008035656 0.1 0.6713062 0.5851292 0.6751244
15 0.008035656 1.0 0.6708204 0.6277907 0.6072610
16 0.008035656 10.0 0.6295020 0.5946899 0.5789442
17 0.013088587 0.1 0.6630773 0.6025217 0.6261960
18 0.013088587 1.0 0.6672180 0.6356523 0.5978122
19 0.013088587 10.0 0.6156558 0.6041164 0.5615667
20ROC was used to select the optimal model using the largest value.
21The final values used for the model were sigma = 0.003796662 and C = 0.1.
22>
23The best parameter for the model is sigma = 0.003796662, and C = 0.1. We use this values to fit the 10% of downsampling data and collect its performance based on test set.
1svm_model = ksvm(loan_status ~ .,
2 data = samp[train_index_training,],
3 kernel = "rbfdot",
4 kpar = list(sigma=0.003796662),
5 C = 0.1,
6 prob.model = TRUE,
7 scaled = FALSE)
8Prediction
1predict_loan_status_svm = predict(svm_model,data_test,type="probabilities")
2predict_loan_status_svm = as.data.frame(predict_loan_status_svm)$Fully.Paid
3ROC and AUC
1rocCurve_svm = roc(response = data_test$loan_status,
2 predictor = predict_loan_status_svm)
3auc_curve = auc(rocCurve_svm)
4> plot(rocCurve_svm,legacy.axes = TRUE,print.auc = TRUE,col="red",main="ROC(SVM)")
5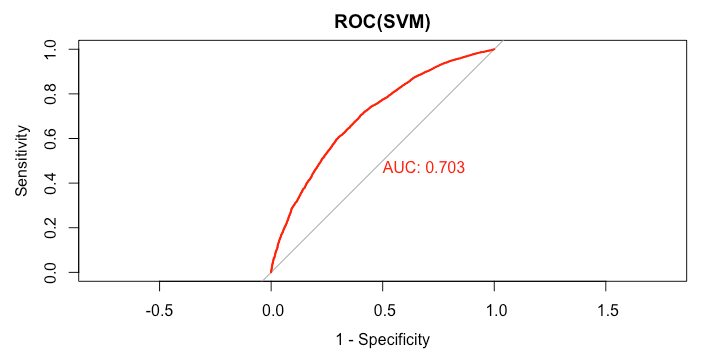
1> auc_curve
2Area under the curve: 0.7032
31predict_loan_status_label = ifelse(predict_loan_status_svm<0.5,"Default","Fully.Paid")
2c = confusionMatrix(predict_loan_status_label,data_test$loan_status,positive="Fully.Paid")
3This is the summary of model’s performance.
1table_perf[2,] = c("SVM",
2 round(auc_curve,3),
3 as.numeric(round(c$overall["Accuracy"],3)),
4 as.numeric(round(c$byClass["Sensitivity"],3)),
5 as.numeric(round(c$byClass["Specificity"],3)),
6 as.numeric(round(c$overall["Kappa"],3))
7 )
8
9> tail(table_perf,1)
10 model auc accuracy sensitivity specificity kappa
112 SVM 0.703 0.635 0.612 0.688 0.257
12>
13