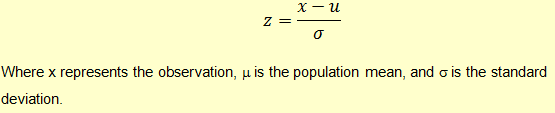How to Remove Outliers in R
An outlier is an observation in a dataset that lies abnormally away from other observations in the dataset. Based on this definition, it is the analyst who decides what constitutes an outlier in the data that he is working with. The analyst observes the data and outlines the characteristics of what is considered normal for an observation. As an example, if your dataset contains heights of men in a city, you may observe that most men have a height in the range of 5 feet to 6 feet. You may keep some margin and say that anyone who is above 6.5 feet is considered an outlier.
While analyzing data, it is sometimes important to remove these outliers as they tend to skew the statistics you’re calculating. In this article, we will learn about how to identify and remove outliers in R programming.
How to Identify Outliers in R
There are two ways we can identify outliers. One is using Interquartile Range (IQR) and the other is using z-scores.
Let’s look at these two methods:
Interquartile Range
Interquartile range (IQR) is the difference between the 1st quartile (25th percentile) and the 3rd quartile (75th percentile). It basically gives us the spread of the middle 50% values in the dataset. For a value to be identified as an outlier the rule of thumb is that the value is outside 1.5 times IQR above the 3rd quartile or 1.5 times IQR below the 1st quartile.
Outlier = Value above Q2 + 1.5IQR Or Value below 1.5IQR
Z-score
We can also identify outliers using z-scores. A z-score reflects how many standard deviations above or below the mean an observation is. A z-score of 2 indicates that the current observation is 2 standard deviations above the mean.
The rule of thumb is that an observation is an outlier if it has a z-score less than -3 or greater than 3.
How to Remove Outliers in R
Now that we know how to identify outliers, let’s learn about how we can remove these outliers from a dataset in R.
For our example, let’s create dataframe that contains some random data.