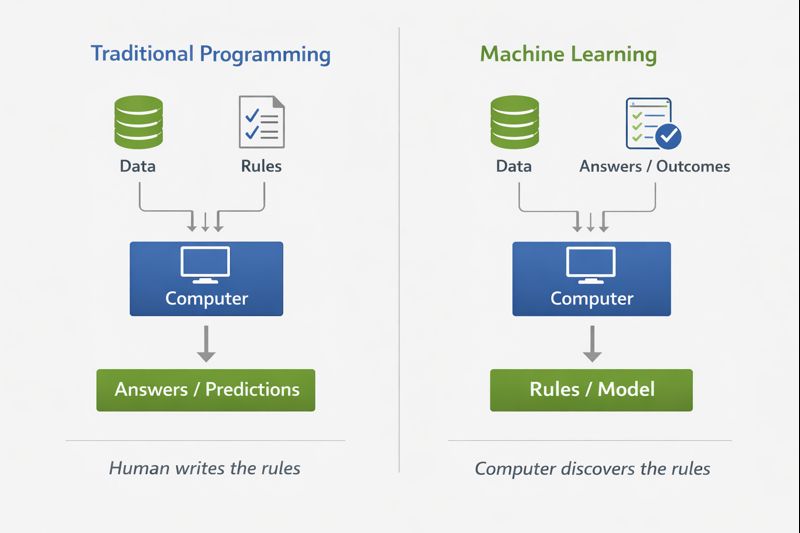
Machine learning has become one of the most influential technologies in modern computing. It represents a fundamental shift in how we approach problem-solving with computers. Rather than explicitly programming rules for a computer to follow, we provide data and let the computer discover the rules itself.
The Problem with Traditional Programming
Consider a bank that wants to predict which loan applicants are likely to default. Using traditional programming, an analyst would study past defaults and write explicit rules:
1IF income < $30,000 AND debt > $50,000 → high risk
2IF employment_years <2 AND loan_amount >
Get the ebook to continue with the full material and included resources.
eBook - Introduction to Machine Learning
Cheatsheet
Worksheet
Interview Q&A
$
100
,
000
→ high risk
3
IF credit_score
<
600
→ high risk
4
.
.
.
5
This approach has limitations. First, the rules quickly multiply. What about applicants with moderate income but excellent credit history? What about self-employed individuals with irregular income patterns? The analyst must anticipate every scenario and write rules for each. Second, the rules interact in complex ways, creating edge cases that require exceptions to exceptions. Third, and most importantly, some patterns in the data are too subtle for humans to articulate. An experienced loan officer might have an intuition about which applicants will default, but could they write down every factor their brain considers? Unlikely.
The Machine Learning Approach
Machine learning takes a fundamentally different approach. Instead of writing rules, you provide the computer with historical data:
Applicant
Income
Debt
Credit Score
Employment Years
Loan Amount
Defaulted?
A
$45,000
$12,000
720
5
$25,000
No
B
$38,000
$65,000
580
1
$40,000
Yes
C
$92,000
$30,000
695
8
$150,000
No
D
$28,000
$45,000
540
2
$35,000
Yes
...
...
...
...
...
...
...
Given thousands of such records, the machine learning algorithm analyzes the data and discovers which combinations of factors are associated with default. It might find that the ratio of debt to income matters more than either value alone, or that credit score below a certain threshold combined with short employment history is particularly risky. These are patterns the algorithm extracts from the data - patterns that might take a human analyst months to discover, if they could discover them at all.
Traditional Programming vs Machine Learning
The fundamental difference is this: in traditional programming, humans provide the rules and the computer applies them; in machine learning, humans provide the data and the computer discovers the rules.
What Machine Learning Actually Does
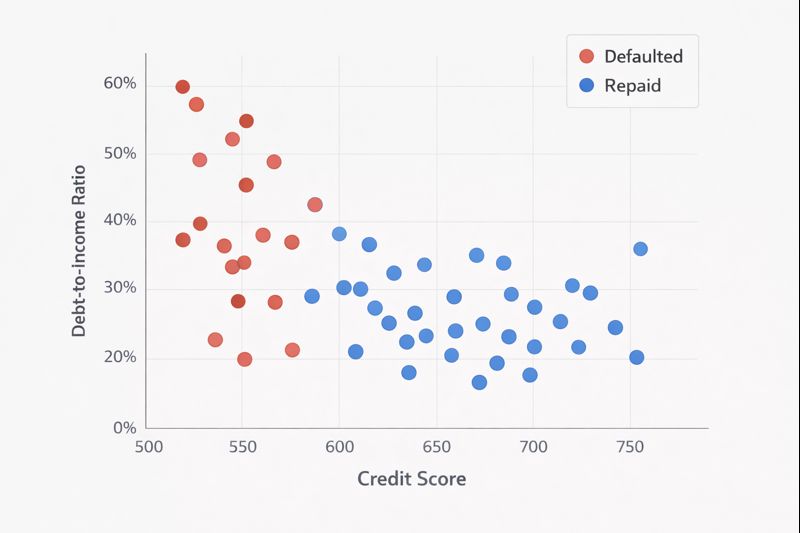
To understand what "discovering patterns" actually means, consider a simplified example. Suppose we have data on 1,000 past loan applicants with just two features: credit score and debt-to-income ratio. We plot each applicant on a graph, coloring those who defaulted in red and those who repaid in blue.
Loan Default Scatter Plot
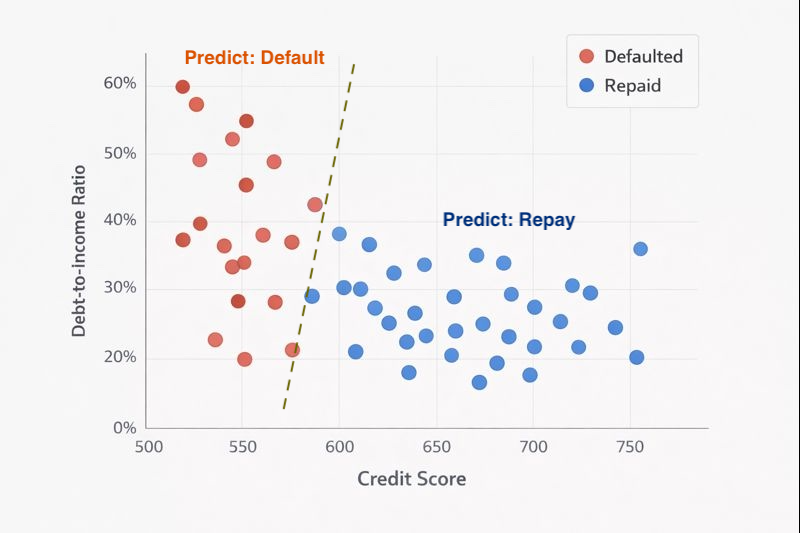
Looking at this plot, you might notice that defaulters tend to cluster in one region (lower credit scores and higher debt-to-income ratios) while successful repayers cluster elsewhere. A machine learning algorithm does something similar: it finds the boundary that best separates the two groups.
Decision Boundary
Once the algorithm has learned this boundary, predicting a new applicant becomes straightforward: plot their credit score and debt-to-income ratio on the graph, and see which side of the boundary they fall on.
This is the essence of machine learning: finding patterns (boundaries, relationships, clusters) in historical data that can be applied to new data. The algorithms vary in sophistication. Some find straight lines, others find complex curves, others work in hundreds of dimensions simultaneously. However, the fundamental principle remains the same.
The Formal Definition
The most widely accepted definition of machine learning comes from Tom Mitchell (1997):
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E."
This definition captures three essential components of any machine learning system:
Task (T): What we want the system to accomplish. In our loan example, the task is classifying applicants as likely to default or likely to repay.
Experience (E): The data from which the system learns. In our example, this is the historical loan data with known outcomes.
Performance (P): How we measure success. We might use the percentage of defaults correctly predicted, or the percentage of overall predictions that are correct.
The system "learns" if, after processing more historical data, it becomes better at predicting which applicants will default. This improvement with experience is what distinguishes machine learning from traditional programming.
Why Machine Learning Now?
The core ideas behind machine learning have existed since the 1950s. Arthur Samuel built a checkers-playing program that improved with experience in 1959. So why has machine learning exploded in the past decade?
Three factors converged:
More data. The digitization of nearly everything - financial transactions, customer behavior, sensor readings, medical records- has created vast datasets. Machine learning algorithms are hungry for data; more data generally means better patterns and better predictions.
More computing power. The algorithms that discover patterns require enormous computational resources. A calculation that would have taken years in 1990 now takes minutes. Graphics processing units (GPUs), originally designed for video games, turned out to be exceptionally good at the matrix operations that machine learning requires.
Better algorithms. Researchers have developed more sophisticated techniques for finding patterns, particularly in complex data like images, text, and speech. Deep learning represents a significant algorithmic advance that has enabled applications previously thought impossible.
These three factors feed on each other. More data justifies investment in better algorithms and hardware. Better hardware makes it practical to work with more data. Better algorithms extract more value from both.
Machine Learning in Finance
Instead of just listing a lot of applications, let's look at one in detail: credit risk modelling.
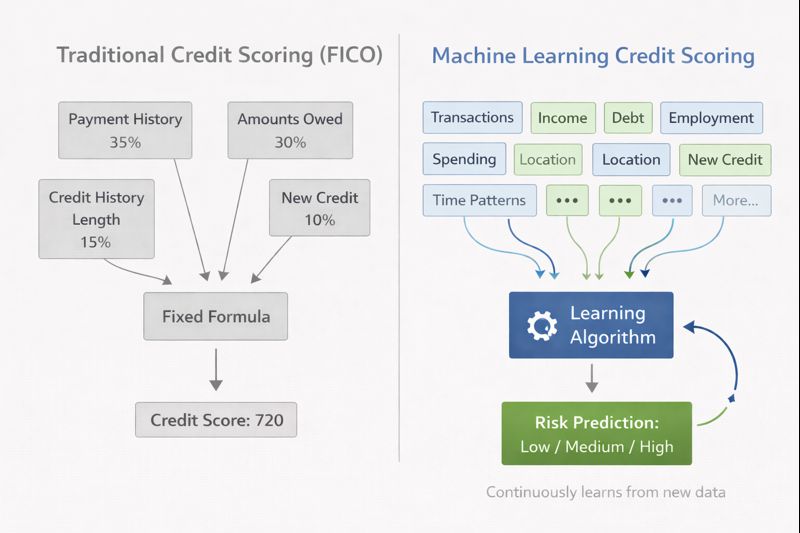
Traditional credit scoring uses a fixed formula. The FICO score, for example, weights five factors: payment history (35%), amounts owed (30%), length of credit history (15%), new credit (10%), and credit mix (10%). This formula was developed by statisticians analyzing historical data, then fixed and applied uniformly.
Machine learning approaches credit risk differently. Instead of a fixed formula, the algorithm continuously learns from new data. It might discover that the relationship between debt and default risk is different for different income levels, or that certain spending patterns in transaction data predict default better than traditional credit bureau data.
traditional-vs-ml-credit-scoring.png
The advantages are significant. Machine learning models can incorporate hundreds of variables and find complex interactions between them. They can adapt as economic conditions change. Patterns that predicted default in 2019 may differ from patterns that predict default in 2024. They can potentially extend credit to people who would be rejected by traditional scoring but who the data suggests are actually good risks.
Machine learning models also have some limitations. These models can be opaque. It may be difficult to explain why a particular applicant was rejected. They can perpetuate or amplify biases present in historical data. They require careful validation to ensure they generalize to new data rather than just memorizing the training examples.
What Machine Learning Is Not
Given the hype surrounding machine learning, it is worth being explicit about what it is not.
Machine learning is not artificial general intelligence. These systems do not "understand" anything in a meaningful sense. A fraud detection system does not know what fraud is. It has learned statistical associations between certain transaction features and the "fraud" label. When patterns change, the system must be retrained.
Machine learning is not infallible. If historical data contains biases, the model learns those biases. If the world changes and patterns shift, predictions become unreliable. A model trained on pre-2008 financial data would not have anticipated the patterns of the 2008 crisis.
Machine learning does not replace domain expertise. Someone must decide what problem to solve, what data to collect, what outcome to predict, and whether the predictions make sense. Machine learning is a tool that amplifies human expertise, not a replacement for it.
Related Terminology
There are a lot of words that are used in the same way as machine learning.
Data mining is the process of finding patterns in large sets of data. It is often used in business.
Predictive analytics focuses on making predictions and appears frequently in business intelligence.
Statistical learning emphasizes the statistical foundations and is common in academic settings.
For practical purposes, these fields address the same fundamental problem: learning patterns from data to make predictions or decisions.