Overfitting occurs when a machine learning model learns the training data too well, memorizing noise and specific patterns that don't generalize to new, unseen data.
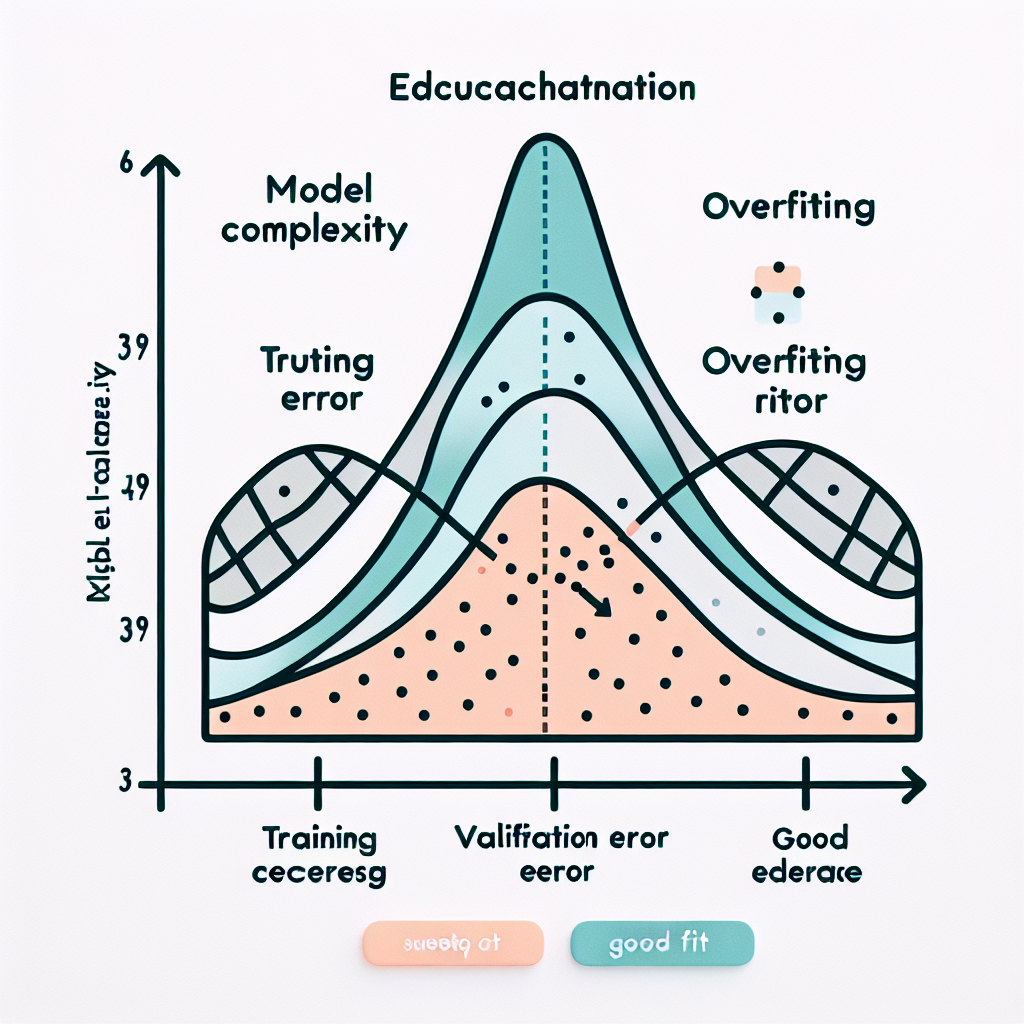
Overfitting happens when a model becomes too complex relative to the amount of training data available. The model captures not only the underlying patterns but also the random noise and outliers in the training set. This results in excellent performance on training data but poor performance on validation or test data.
Common causes include having too many parameters relative to training samples, insufficient regularization, or training for too many epochs. The model essentially memorizes the training examples rather than learning generalizable patterns.
The key indicator of overfitting is a large gap between training and validation performance, where training accuracy continues to improve while validation accuracy plateaus or degrades.
A polynomial regression model with degree 20 fitted to 25 data points might achieve perfect training accuracy by memorizing each point, but perform terribly on new data because it learned the noise rather than the underlying trend.
1# Example: Detecting overfitting