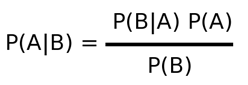Bayes Theorem – Calculating Conditional Probabilities
The Situation
The field of science attempts to answer the following question which arises very often. Given a set of data and observations regarding them the law surrounding the type of data needs to be deduced. In other words the model the fits the data description needs to be derived.
Broadly speaking there are two different approaches to this type of problem. The first one is when a model is assumed from the behavior determined from the observations and the probability of getting the data out of the model is calculated. The other approach aims to find the probability of the model given the data. The first approach is called the Fequentist approach and the second one is called the Bayesian method.
The two methods are contrasted by their characteritics which are listed below:
Frequensitst method
- A model is assumed but the parameters of the model which are fixed may be unknown.
- Data errors that might be random in nature are possible but they have a certain probability distribution for example Gaussian.
- Fitting the model to the data is done by the mathematical methods.
Bayesian Method
- The model is never assumed and there are no true parameters as well. All parameters are however treated as random variables with probability distributions
- Since the model parameters themselves are random with their own distribution, the random errors in data have no probability distribution
- Fitting the data to the model is done by the mathematical methods.
- Both methods give the same answer in the real world but it may be argued that the Bayesian method is more applicable to answering such real-life questions.
The Theorem
Bayes theorem can be represented by the following equation:
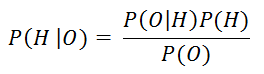
Where:
- H is the Hypothesis and O is the observation.
- P (H|O) is the Posterior Probability of H, i.e., the probability of a hypothesis (H) given an observation (O). This represents your updated degree of belief.
- P(O|H) is the likelihood of H, i.e., the probability of an observation given a hypothesis. In other words, the probability that the hypothesis confers upon the observation.