Ask questions about this lesson and get instant answers.
Relationship between AI, Machine Learning, and Deep Learning
When people talk about machine learning, sometimes that will use the terms AI, machine learning, and deep learning interchangeably. However, these concepts are not the same, even though they are related terms. Let's look at how they relate to each other.
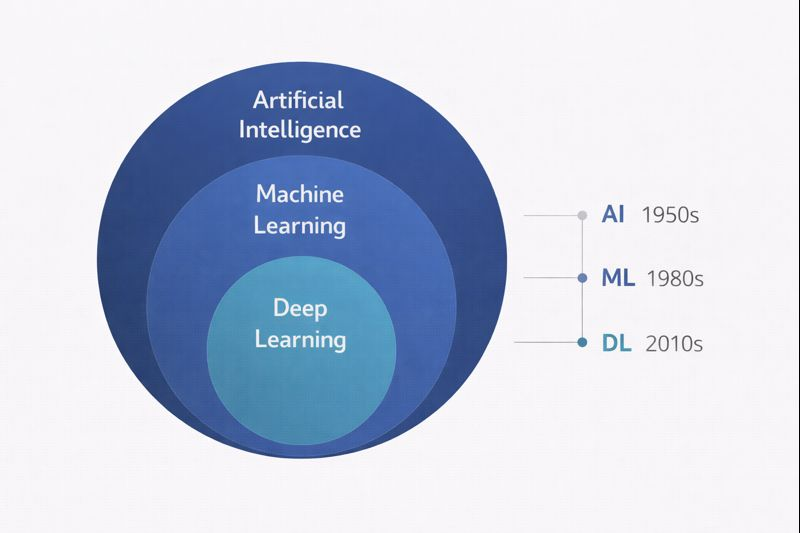
These three terms form a nested hierarchy. Artificial Intelligence is the broadest category. Machine Learning is a subset of Artificial Intelligence. Deep Learning is a subset of Machine Learning.
AI, Machine Learning, Deep Learning hierarchy
This means all deep learning is machine learning, and all machine learning is artificial intelligence. But the reverse is not true. There are AI techniques that are not machine learning, and there are machine learning techniques that are not deep learning.
Artificial Intelligence
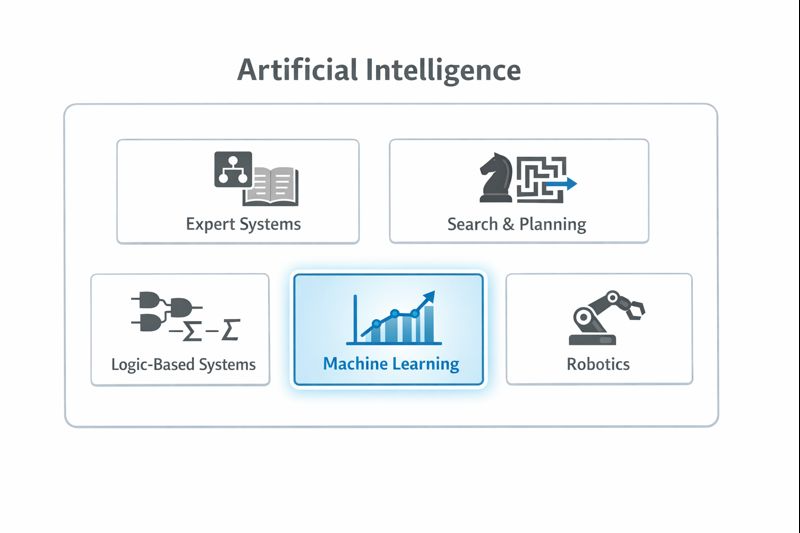
Artificial Intelligence refers to any technique that enables computers to mimic human intelligence. This is a broad definition that encompasses many approaches developed over the past seven decades.
The field of AI began in the 1950s with ambitious goals: create machines that can reason, plan, learn, and understand language. Early AI researchers pursued these goals through various approaches, many of which did not involve learning from data at all.
Expert Systems were a dominant AI approach in the 1980s. These systems encoded human expert knowledge as explicit rules. A medical diagnosis expert system, for example, might contain thousands of rules like: "IF patient has fever AND patient has cough AND chest X-ray shows infiltrates THEN consider pneumonia." These rules were written by humans after interviewing domain experts. The system did not learn them from data.
Search and Planning Algorithms enable computers to find solutions by systematically exploring possibilities. A chess program that evaluates millions of possible move sequences uses AI, but it may not use machine learning; it applies fixed rules about piece values and board positions that were programmed by humans.
Logic-Based Systems use formal logical reasoning to derive conclusions from premises. If the system knows "All mammals are warm-blooded" and "A whale is a mammal," it can conclude "A whale is warm-blooded." Again, no learning from data is involved.
These approaches are all artificial intelligence, but they are not machine learning. The distinguishing feature is whether the system learns patterns from data or follows rules explicitly programmed by humans.
AI Approaches
Machine Learning: Learning from Data
Machine learning is the subset of artificial intelligence where systems learn patterns from data rather than following explicitly programmed rules. This is a powerful approach because it can handle problems too complex for humans to manually encode.
Within machine learning, there are many different techniques. Some have been around for decades and are called "classical" machine learning. Others emerged more recently.
Machine Learning includes algorithms like:
Linear and Logistic Regression: Finding relationships between variables
Decision Trees: Learning rule-based classifications from data
Support Vector Machines: Finding optimal boundaries between classes
k-Nearest Neighbors: Classifying based on similarity to known examples
Naive Bayes: Probabilistic classification using Bayes' theorem
Random Forests: Combining multiple decision trees for better accuracy
These algorithms were developed primarily between the 1960s and 2000s. They remain widely used today because they are fast, interpretable, and work well for many problems, especially when data is limited or when understanding the model's reasoning is important.
These machine learning algorithms typically require humans to specify which features (variables) the algorithm should consider. A fraud detection model using classical ML might be given features like transaction amount, time of day, merchant category, and distance from the cardholder's home. The algorithm learns how these features relate to fraud, but a human decided which features to include.
Deep Learning: Learning Features Automatically
Deep learning is a powerful subset of machine learning built on the concept of neural networks with many layers. The "deep" in deep learning refers to the depth of these networks, the number of layers between input and output.
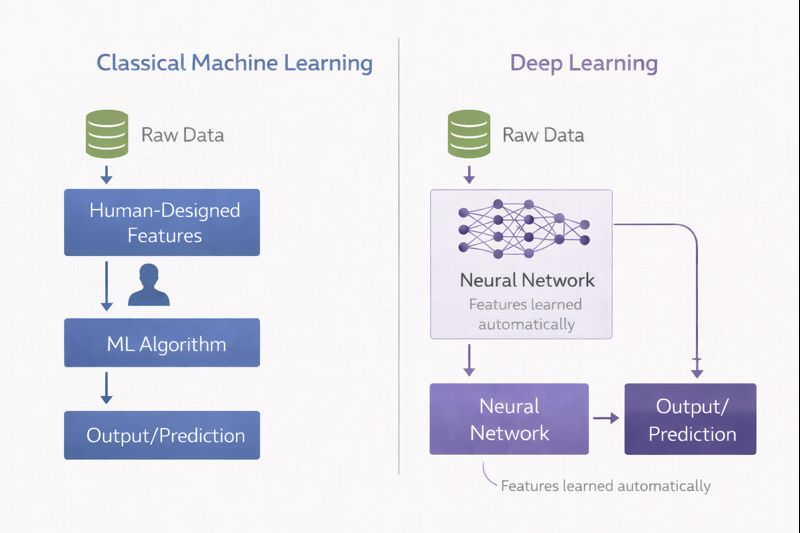
The key innovation of deep learning is automatic feature learning. Instead of humans specifying which features matter, the neural network learns to extract relevant features directly from raw data.
Consider image recognition. A classical machine learning approach might require humans to define features: edge patterns, color histograms, texture measurements. A deep learning approach takes raw pixel values as input, and the network learns to identify edges in early layers, then shapes, then object parts, and finally complete objects in later layers. The features emerge automatically from the data.
Classical ML vs Deep Learning
This automatic feature learning is why deep learning has transformed fields like computer vision, speech recognition, and natural language processing. These domains involve complex, high-dimensional data (images, audio, text) where designing features manually is extremely difficult. Deep learning extracts patterns that humans might never think to look for.
However, deep learning has significant requirements:
Large amounts of data. Deep neural networks have millions or billions of parameters to learn. Training them effectively requires correspondingly large datasets, often millions of examples.
Substantial computing power. Training deep networks requires extensive matrix calculations, typically performed on specialized hardware like GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units).
Less interpretability. A decision tree can be read and understood by a human. A neural network with millions of parameters cannot.
When to Use What
The choice between classical machine learning and deep learning depends on the problem:
Factor
Classical ML
Deep Learning
Data availability
Works with smaller datasets (thousands of examples)
Requires large datasets (hundreds of thousands to millions)
Feature engineering
Requires human expertise to select features
Learns features automatically
Interpretability
Often interpretable (decision trees, linear models)
Generally opaque
Computing resources
Runs on standard hardware
Often requires GPUs
Data type
Works well with structured/tabular data
Excels with images, audio, text
In finance, classical machine learning remains dominant for many applications. Credit scoring, fraud detection, and risk modeling typically use tabular data (numbers in spreadsheets) where classical algorithms perform well and interpretability matters. Deep learning is more common in applications involving unstructured data: analyzing news articles for sentiment, processing documents, or detecting anomalies in trading patterns.
Data Science
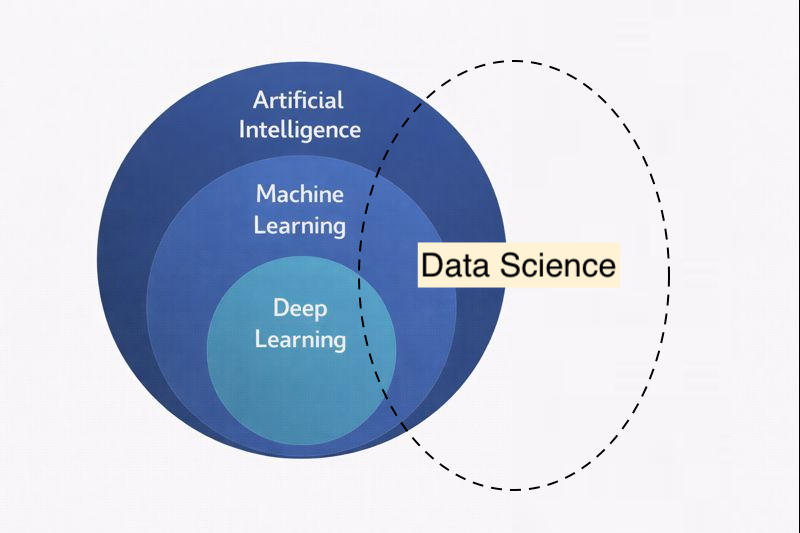
Data Science is an interdisciplinary field that draws upon multiple domains to extract insights and knowledge from data. Unlike the nested hierarchy of AI, ML, and DL, data science is better understood as a field that intersects with and utilizes all three, while also incorporating other essential disciplines.
Data Science Intersection.png
Data science involves not just AI techniques but also statistics, data analysis, visualization, and domain expertise to extract meaningful insights from data. A data scientist working on a credit risk problem needs:
Statistics and Mathematics. Understanding probability distributions, hypothesis testing, statistical significance, and the mathematical foundations that underpin machine learning algorithms. This includes statistical techniques like regression analysis.
Programming and Computer Science. The ability to work with data programmatically, build data pipelines, query databases, and implement algorithms. Data scientists must be comfortable manipulating large datasets and automating analytical workflows.
Data Visualization. Communicating findings through charts, graphs, and interactive dashboards. Visualization is essential both for exploratory analysis (understanding what the data contains) and for presenting results to stakeholders who may not have technical backgrounds.
Domain Expertise. Understanding the business context in which the analysis operates. A data scientist building a fraud detection model needs to understand how fraud actually occurs, what patterns are meaningful, and what the cost of different types of errors might be. Without domain knowledge, even technically sophisticated models can be useless or misleading.
Machine Learning and AI Techniques. Building predictive models, whether using classical machine learning algorithms or deep learning, depending on the problem requirements.
The relationship between data science and the AI/ML/DL hierarchy is one of overlap and utilization. Data science draws upon machine learning as a powerful tool for prediction and pattern recognition, but it also uses many techniques that are not machine learning at all: descriptive statistics, data visualization, and domain-driven analysis.
In practice, a data scientist might spend 80% of their time on data collection, cleaning, and exploration. This work involves programming and statistics but not necessarily machine learning. The actual model building might represent only 20% of the effort. This reality is important to understand: machine learning is a powerful technique, but it is embedded within a larger process that requires diverse skills.
The distinction matters for organizations. Hiring a "machine learning expert" will not solve data problems if the data is messy, incomplete, or poorly understood. Effective data science requires the full range of skills: statistical thinking, programming ability, visualization expertise, domain knowledge, and machine learning proficiency, all working together.
Related Fields and Terminology
Several other terms appear in this landscape:
Artificial Neural Networks (ANNs) are the foundation of deep learning. They are computing systems inspired by biological neural networks, consisting of connected nodes (neurons) organized in layers. Not all neural networks are "deep." Shallow networks with one or two hidden layers have been used since the 1980s.
Predictive Analytics is a business term for using data to predict future outcomes. It typically involves machine learning but emphasizes the business application rather than the technical method.
Big Data refers to datasets too large or complex for traditional data processing tools. Machine learning and big data often go together. Large datasets enable effective machine learning, and machine learning provides tools to extract value from big data.
Summary of the Hierarchy
To clarify the nested relationship:
Artificial Intelligence is any technique enabling computers to mimic human intelligence. This includes:
Expert systems (rules written by humans)
Search and planning algorithms
Logic-based reasoning
Machine learning
And other approaches
Machine Learning is the subset of AI where systems learn from data. This includes:
Deep Learning is the subset of machine learning using multi-layer neural networks that automatically learn features from raw data.
Understanding these distinctions helps you evaluate technologies appropriately. When a vendor claims their product uses "AI," you can ask: Is it rule-based or does it learn from data? If it learns from data, what kind of algorithm does it use? Does it require large datasets and significant computing resources? These questions lead to much more productive conversations about what the technology can and cannot do.